这是一个Linux TCP SYN Cookies导致的服务端丢数据问题,其特殊之处在于:数据丢失时,协议栈、应用层socket接口均无任何报错。
注:本文来源于生产环境遇到的真实案例,在排查过程中查到了国外一个博客的资料:https://wpbolt.com/syn-cookies-ate-my-dog-breaking-tcp-on-linux/ 想了解问题根源的朋友可以直接去看资料。
问题场景
我们线上有一个PyTorch的DDL作业,某次进行扩容后(训练机器数量增加至几百台,每台机器跑8个作业进程),作业启动时在初始化阶段大概率会遇到TCP连接reset,导致作业无法进行。
经过初步检查,问题发生在TCPStore中。TCPStore是PyTorch内置的一个极简数据库,启动作业时,所有worker进程都与worker0的TCPStore建立TCP连接,存储自身的信息并读取其他进程的信息。链接建立的过程中worker0为服务端,其他worker为客户端。
根据报错信息确认,是客户端被服务端(worker0)给reset掉了。
问题定位
先说一下TCPStore的协议是一个非常简单的二进制格式,如下:
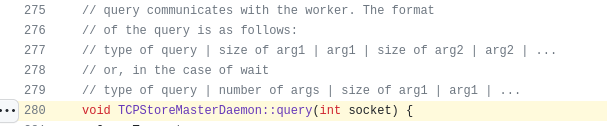
其中第一个字节是query类型,定义如下:
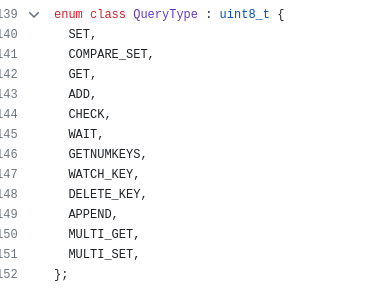
阅读源码发现,初始化时,每个作业进程会向worker0固定发送一个ADD类型的请求,其key为"init/",即第一个请求为:
3(1 bytes) | 5(8 bytes) | 'init/' | 1(8 bytes)
上面是一些前置知识。由于PyTorch自身的调试日志较少,现场没发现有用的信息。我们在TCPStore源码中,网络IO流程的相关节点进行日志打点,并结合GDB, 定位到问题的直接原因:
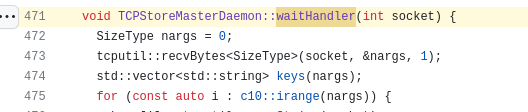
如图,在waitHandler中,会调用tcputil::recvBytes<SizeType>来读取一个8字节的长度,该长度代表WAIT请求的参数个数nargs,接下来使用该数值创建一个vector存储各个参数。
我们观察到nargs读入了一个非常大的数(7566047373982433280,记住这个数字),导致创建vector时直接报内存不足的异常,上层函数捕获到异常后会强制reset该连接。
那么新的问题来了:
- 根据之前所说,客户端连接后会发一个ADD(类型值是3)请求,为什么出问题的地方反而在WAIT(类型值是5)的处理函数中?
- 为什么WAIT的参数个数会是一个异常的数据?
根据经验,这里面有几种可能,常见的比如某处内存溢出导致数据错乱。但考虑到PyTorch是一个十分成熟的项目,该模块也是基础模块之一,似乎不应该出类似bug;我们又把该部分相关代码通读一遍,其设计十分简洁明朗,也没有发现这种问题。 是不是服务端没问题,但是客户端生成的数据有误?我们开始进行抓包,发现ADD请求的数据本身确实没问题,但是是分为两个包发过来的:

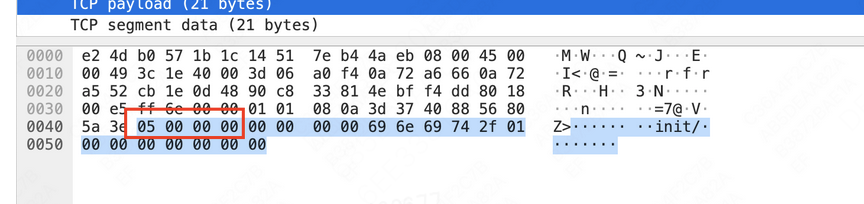
还记得前面那个非常大的数据吗?7566047373982433280 = HEX(6900000000000000),刚好是第二个包的2~9字节;而第二个包首字节是5,刚好是WAIT请求的类型值。
到这里几乎可以确定,客户端发送的请求是没问题的,在网络层面分为了两个包;而服务端不知道为何,“无视”了第一个包的数据,错把第二个包当作最开始的数据,导致数据解析出现问题。难道是linux的协议栈出bug了?
TCP SYN Cookies的问题
回忆问题一开始出现的场景,我们是把作业规模扩大后才大概率触发该问题。问题范围缩窄到TCP协议栈后,我们重点查看了系统协议栈相关日志,发现基本只出现过一类日志:
TCP: request_sock_TCP: Possible SYN flooding on port 3400. Sending cookies. Check SNMP counters.
以此为线索,经过查阅各种资料,终于找到了问题根源。
本文不多介绍TCP SYN Flood, 可以参考这里一篇非常不错的文章:https://segmentfault.com/a/1190000019292140
SYN Cookies本质是服务端根据连接信息(例如时间戳和MSS),按照一定格式编码出一个初始seq序号,在后续收到客户端ack时,根据这个序号能反推出连接信息。
Linux的SYN Cookies编码方式和RFC 4987中所描述的不同。在Linux中,编码32位Cookie的方式如下:
Hash(五元组) + (时间戳 << 24) + 客户端序号 + ((Hash(五元组,时间戳) + MSS序号) & 0x00FFFFFF)
在协议栈收到客户端ACK包时,会解码Cookie,判断是否是一个正确合法的连接。其中,MSS序号的解码方式为:
Cookie - Hash(五元组) - (时间戳 << 24) - 客户端序号 - (Hash(五元组,时间戳) & 0x00FFFFFF)
其实就是做减法(还有验证时间戳的逻辑,为了简化就不写了)。这样得到的MSS序号实际是个MSS Entry。Linux内核中有个MSS表,如下:
static __u16 const msstab[] = {
536,
1300,
1440, /* 1440, 1452: PPPoE */
1460,
};
可以看到里面有4个Entry。解码后,协议栈会判断MSS Entry的合法性。如果得到的MSS Entry 不在0、1、2、3当中,就认为是非法值;否则认为是合法值,根据Entry查表拿到MSS值。另外,在现在Linux内核中,MSS Entry最常见的值是3。
问题根源
接下来考虑一个问题:假如解码Cookie之前发生丢包,会出现什么后果?
例如:客户端发送的首个包有3个字节,并且该包被丢失,服务端处理的cookie实际是第二个包。根据上面计算MSS的流程,这种情况只会影响其中的客户端序号,导致计算出的MSS Entry比正常值小3。由前面所说,MSS Entry正常值大概率就是3,因此这里计算出的MSS Entry很可能就是3-3=0
0,依然是个合法的MSS Entry,也就是说此时协议栈并不知道他接收的实际上是第二个包,协议栈以为这就是个客户端的首个ACK包!在我们遇到的问题场景中,首个包只有1字节,服务端协议栈根据第二个包计算出的MSS Entry为2,也是个正常值,因此错把第二个包当了首包进行建连,第一个字节因此而丢失了。
当然如果首包长度是4,那么服务端就能根据MSS Entry发现问题了。
那么剩余一个问题,客户端的第一个ACK包是怎么丢的?还记得问题是由于扩大了作业规模才触发,也就是TCP并发连接数增加;而我们机器上配置的somaxconn = 128,导致规模扩大后队列很容易就满了然后协议栈主动丢包,第一个包就是这么丢的。
关于syncookies、somaxconn和tcp_max_syn_backlog,这里有一个很不错的文章:https://www.alibabacloud.com/blog/tcp-syn-queue-and-accept-queue-overflow-explained_599203
总的来看linux的这个设计就很奇怪,像SYN Cookies这种并不罕见的功能选项居然会有这种设计漏洞。并且,虽说案例中有队列数配置过小的因素,但是从我们的朴素认知来看,TCP协议应该表现为:只要交给应用层的数据就应该保证是对的,否则就算直接报错甚至断连,也不应该给上面交付不完整的错误数据;而不是像这个问题一样,一些本来只应该影响性能的配置,却导致了上层在没有任何察觉的情况下,收到了错误的数据。